Get a Real Job
During the destitution that was the period of last few months for me, I came across many a job posting that seemed rather fishy to me. There even was one enterprise that reduced the stipend to about 10% of what it was when I applied, and once I finished the screening, pretented as if it was always that low. Fortunately, I never submitted the screening. So, I decided to build a classifier that would detect fake job postings. Thankfully, this dataset was available to work on. My entire notebook, including an outline of the thought process is available in my Kaggle kernel. If you like it, please upvote it. That would really help me.
Data Handling
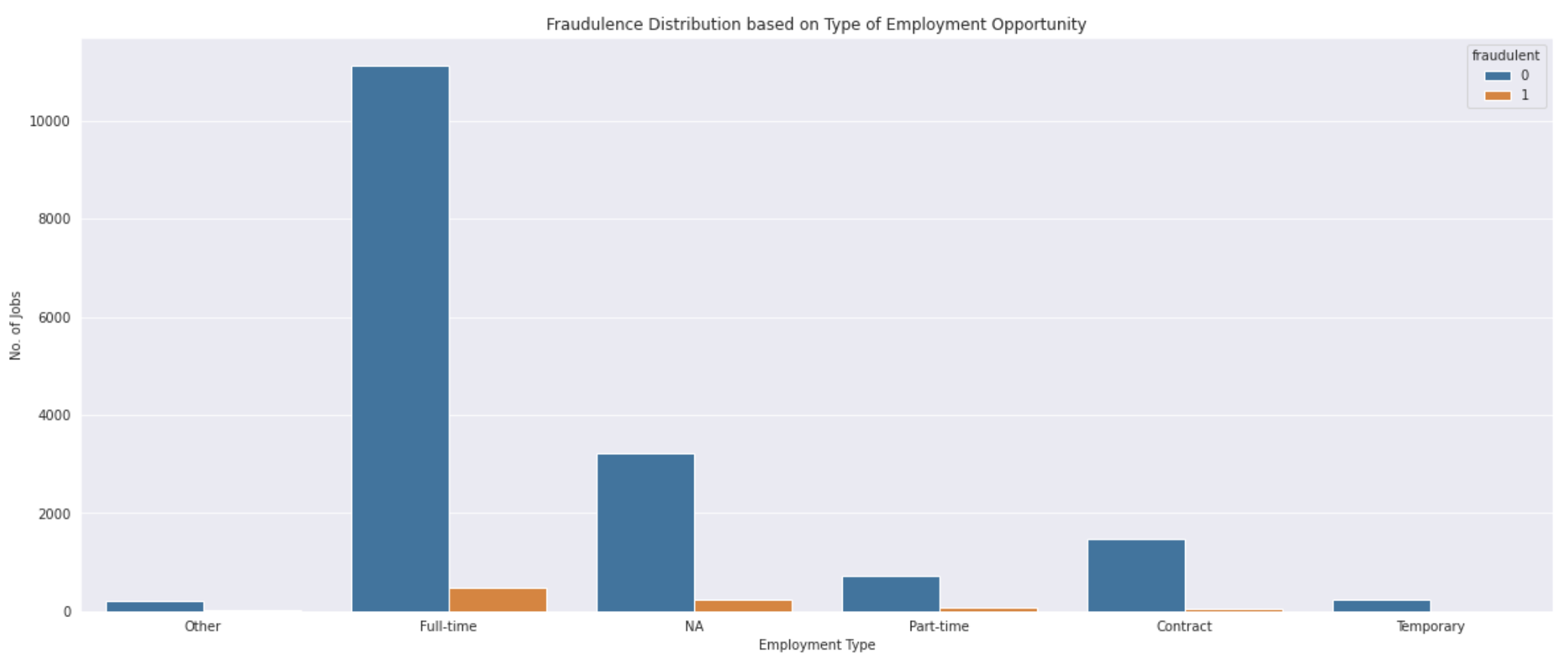
The data has 18000 job descriptions out of which 800 are fake. So, clearly there is a class imbalance. Now working with such a class imbalance can pose a threat to the validation of the model. Since a significantly large number of job postings are, as a matter of fact, real, the model can always predict that the test instance is real and basically get away with it. There are different manœuvres for it, however I chose to opt for three: use Cohen’s Kappa as a metric in lieu of simple percentage based accuracy, use F1 score in lieu of simple percentage based accuracy, and a little sub-sampling never hurts.
- Cohen’s Kappa helps because it basically takes into consideration the possibility of agreement by chance. It gives the value of agreement between two raters who each classify a number of items or instances into separate classes or groups. So, it is a good method to check disproportionate advantage of one class over another.
- F1 Score, simply, is the harmonic mean of precision and recall. So, in lay terms, it seeks to neutralise the effects of class imbalance.
- Sub-sampling the entire dataset helps in giving the class with less instances an equal footing with its counterpart.
Preparing a Language Model
The logical first step of handling any task that involves natural language is to prepare a language model out of it. In lay terms, a language model is nothing but an autocomplete service. It tries to predict the next word (token) of the text. It does so in order to get the essence of the type of texts, to seek to identify the fake and real job postings, in this case. I prepared an LSTM based language model learner using fastai with the metrics being simple accuracy and perplexity.
- Here, since one is simply predicting the next token, simple accuracy works just fine.
- Perplexity helps give the magnitude of uncertainty in a specific text.
The language model also comes pretrained with the entirety of the text from Wikipedia, which helps it recognise the basic nuances of the general English language. Training it on this dataset will further converge its capability to recognise the specific nuances of the fashion in which text is written for job postings. Now, there are some decisions to be made:
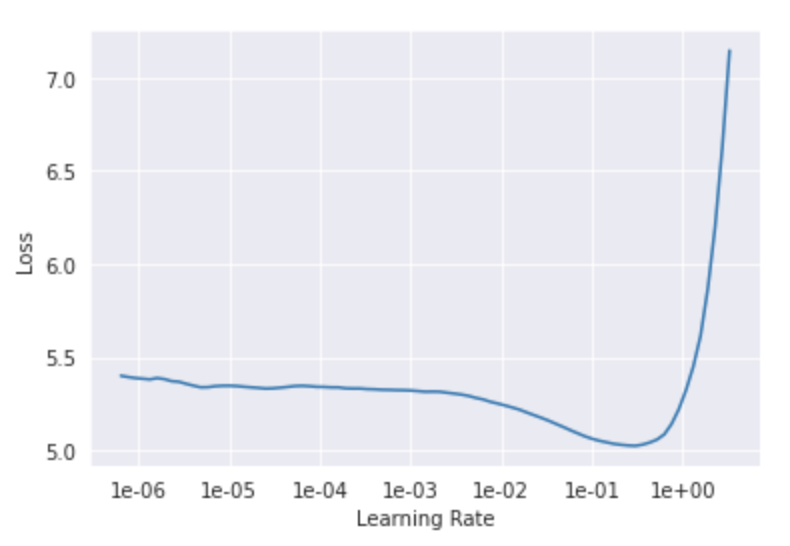
On observing the behaviour between the learning rate and the loss function, it is seen that an optimum loss is achieved right before its explosion, at just under the value 1. This is a dangerous situation to be in. Since if the learning rate somehow reaches 1, the loss is going to explode. So, I choose a maximum learning rate of 0.1, this ensures that loss will not explode while also keeping it fairly optimum.
I also use Mixed Precision Training which helps in decreasing the training time. Mixed precision is the use of both 16-bit and 32-bit floating-point types in a model during training to make it run faster and use less memory. By keeping certain parts of the model in the 32-bit types for numeric stability, the model will have a lower step time and train equally as well in terms of the evaluation metrics such as accuracy.
Further, in order to actually train the language model, I use the Cyclical Annealing method of fitting. At this point, it is established that this method is much better than the standard fitting approach since it explores the entire space of loss function to ensure a convergence at a global extremum instead of a local extremum.
Training for the language model is done for 5 generations which takes roughly 20 minutes and we reach an accuracy of 50.63% and a perplexity score 14.414. This is great because the language model can predict every other word correctly having a 50% accuracy.
Building the Classifier
As mentioned above, sub-sampling is done where 1400 real postings and all the fake postings are selected. Mind you that the data is still not balanced, but it is much less imbalanced. And for the metrics, I use the macro averaged F1 score and the quadratic weighted Cohen’s kappa.
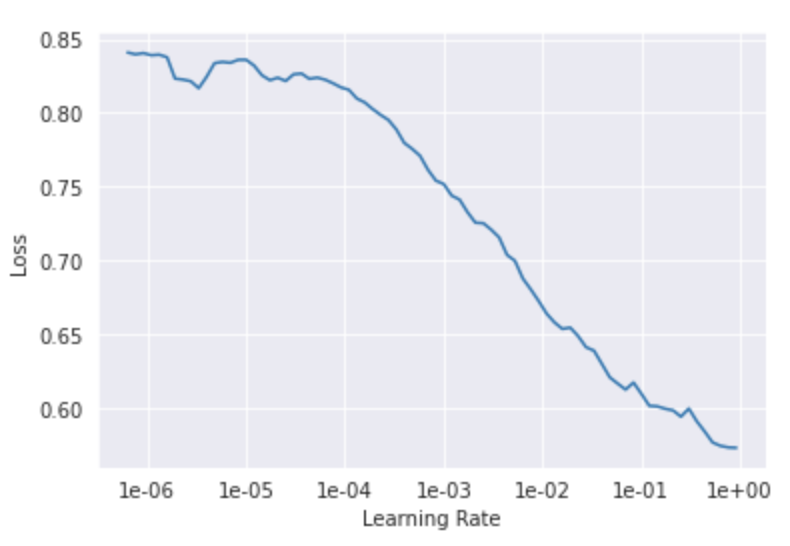
Things are easier now that the learning rate for this classification follows a more-or-less smooth downward trajectory against the loss function. The model is trained for 10 generations which takes well under 2 minutes (1 minute 40 seconds to be precise) and finally the training loss comes out to be 0.269, validation loss 0.187, F1 score 0.9254 and Cohen’s kappa 0.855.
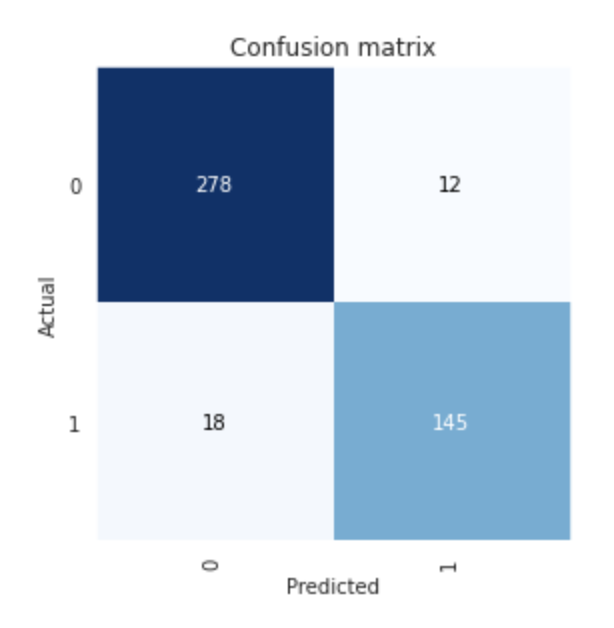
Check out my Kaggle kernel for detailed code and analysis.